Benchmarking and scaling subscribers
March 15, 2024 | Adam Turnbull
Introduction
Diffusion is a great piece of software for distributing data, but how it works is a little different to traditional messaging platforms. In particular, it’s better at sending only the data that is required, rather than sending everything and leaving it to the consuming clients to drop what they don’t need.
As a consequence, it scales really well to handle many subscribers – because the server is sending less data it can divide its attention across more clients.
The core to this is Diffusion’s topic model. Where normally you might expect a small number of topics (or channels) containing a flood of data, in Diffusion we categorise the data and split it into related packets of information in a hierarchical topic tree. These topics are relatively lightweight and it is not unusual to see a Diffusion server containing millions of topics. Each one can be subscribed to individually, so a client can be very specific about what they are interested in receiving.
The unique feature of Diffusion that we’ll see in this article is how it reduces the amount of data transmitted to clients by using deltas of change. If a client has received the data for a topic, and that topic is then subsequently updated, Diffusion is intelligent enough to know that it only needs to send the difference between the old value and the next. The client library will then recreate the full value for the application to consume.
Scenario
Our use case involves sending JSON data from publishers to subscribers. Here is a sample of one JSON message:
{
"timestamp": "1570097621137",
"pairName": "EUR-USD",
"pairs": [
{ "timestamp": "1570097621137",
"pairName": "EUR-USD",
"tiers": [{ "high": "1.09407", "open": "1.09625", "low": "1.09741",
"bid": { "big": "1.09", "points": "485" },
"offer": { "big": "1.09", "points": "486" }},
{ "high": "1.09407", "open": "1.09625", "low": "1.09741",
"bid": { "big": "1.0355", "points": "485" },
"offer": { "big": "1.1445", "points": "486" }},
{ "high": "1.09407", "open": "1.09625", "low": "1.09741",
"bid": {"big": "0.981", "points": "485" },
"offer": { "big": "1.199", "points": "486" }}]},
{ "timestamp": "1570097629409",
"pairName": "EUR-GBP",
"tiers": [{ "high": "0.88951", "open": "0.89102", "low": "0.89225",
"bid": { "big": "0.89", "points": "087" },
"offer": { "big": "0.89", "points": "091" }},
{ "high": "0.88951", "open": "0.89102", "low": "0.89225",
"bid": { "big": "0.8455", "points": "087" },
"offer": { "big": "0.9345", "points": "091" }},
{ "high": "0.88951", "open": "0.89102", "low": "0.89225",
"bid": { "big": "0.801", "points": "087" },
"offer": { "big": "0.979", "points": "091" }}]}
]
}Each subsequent message for a topic will differ by a small amount to the previous one, e.g. the “points” value of one of the tiers may change.
Test cases
The data source for all the scenarios will remain constant; we will set up 100,000 topics in Diffusion and update them at an aggregate rate of 20,000 updates per second, which means on average, any given topic is updated once every 5 seconds. The size of the data in each topic will be around 1,000 bytes, as shown above.
When we run benchmarks with Diffusion, we typically target an end-to-end latency of under 50ms per update from the point where it is sent to Diffusion, to where a client receives the update.
All testing is performed on AWS, with a Diffusion server using a c6in.4xlarge instance, i.e. 16 vCPUs and 32GB of memory.
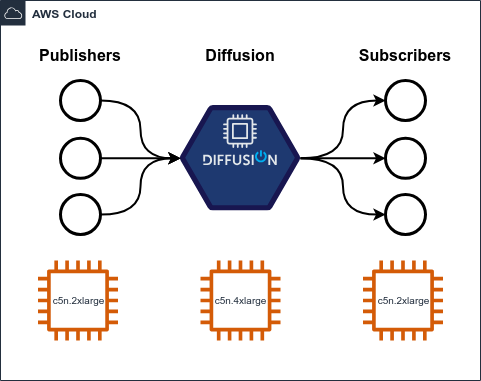
Subscribers are hosted on 6xin.2xlarge servers. This is not typical of a “real-world” deployment; you might have thousands of connected clients, each on their own device (server, desktop, laptop, phone, etc.). Since we don’t have a practical way of running up this many individual machines, we simulate as best we can with multiple clients on a smaller number of machines.
Scaling the number of subscribers
First of all, let’s see how a single instance of Diffusion copes with different numbers of subscribers. With this test, we will also disable delta calculations for the updates, which keeps us in line with other messaging / event platforms and will let us compare the performance when we enable deltas in the next test.
| Number of clients | Subscriptions per client | Effective updates/sec per client | Total events broadcast per second | Diffusion CPU usage | End-to-end latency | Bandwidth (outbound) |
|---|---|---|---|---|---|---|
| 5,000 | 100 | 20 | 100,000 | 2 CPUs | 1 ms | 600 Mbps |
| 10,000 | 100 | 20 | 200,000 | 3 CPUs | 1 ms | 1200 Mbps |
| 20,000 | 100 | 20 | 400,000 | 5 CPUs | 1 ms | 2400 Mbps |
This looks good – a clear, predictable and linear increase in CPU usage and outbound bandwidth as the number of clients increases, with the latency remaining constant.
When benchmarking, it’s very useful to know at what point the system under test starts to break down. We continued testing and plotted the data all the way out to 50,000 concurrent sessions – well above the parameters of the test:
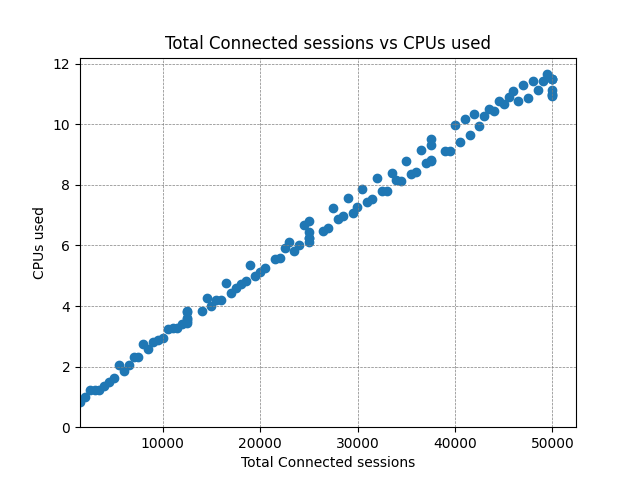
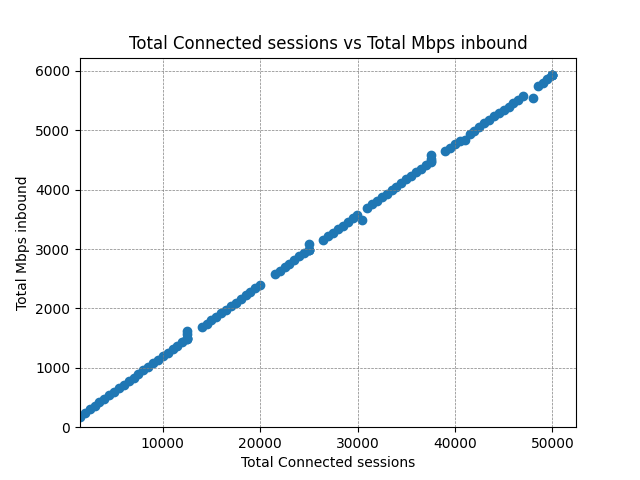
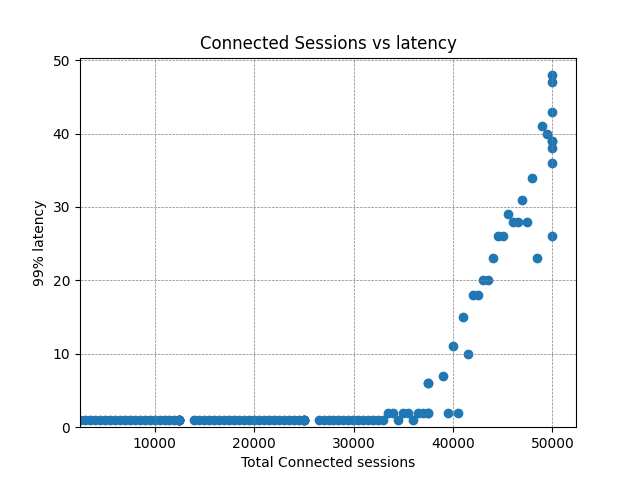
The CPU usage is scaling nicely, and outbound data is being published at the expected rate throughout (note: inbound here is from the perspective of the consumers – it is outbound from Diffusion). However there is a clear increase in latency at around 35,000 concurrent clients, so we can say with a reasonable level of confidence that this is the limit for this particular configuration. In the real world you’d likely be happy to support 20,000 clients like this with the knowledge that there’s plenty of headroom to cope with bursts of activity.
Enabling deltas on messages
Let’s now run the same test again, but enable the delta calculations on the messages. As mentioned, this is a technique that Diffusion uses to reduce the amount of data being sent over the network – very useful if you are paying for data when it leaves a public cloud.
We’ll actually get two values for the savings from delta calculations: the savings in terms of absolute bandwidth (measured at the network level) and the savings on the payload. The former includes TCP/IP headers and other enveloping which can’t be reduced, whereas the latter only measures the savings on the Diffusion topic data itself.
| Number of clients | Subscriptions per client | Effective updates/sec per client | Total events broadcast per second | Diffusion CPU usage | End-to-end latency | Bandwidth usage | Bandwidth saving | Payload saving |
|---|---|---|---|---|---|---|---|---|
| 5,000 | 100 | 20 | 100,000 | 2.5 CPUs | 1 ms | 103 Mbps | 83 % | 90 % |
| 10,000 | 100 | 20 | 200,000 | 3.5 CPUs | 1 ms | 206 Mbps | 83 % | 90 % |
| 20,000 | 100 | 20 | 400,000 | 5.6 CPUs | 2 ms | 412 Mbps | 83 % | 90 % |
For a small increase in CPU cost and latency, we’ve managed to save ourselves a significant amount of network bandwidth. It should be noted that there are several factors that might affect these numbers; the size of a topic update message, the number of changes from one update to the next and the distribution of changes within the message all play their part. If the delta calculation is particularly expensive to perform, Diffusion will dynamically choose to back off and produce less optimal deltas to free up CPU for other tasks, at the expense of increased bandwidth. It should also be noted that the delta calculation can be offloaded to the publisher processes to allow for better distribution and scalability. But that’s something to dive into another day.
As with the previous test, here are the results plotted out to 50,000 concurrent clients:
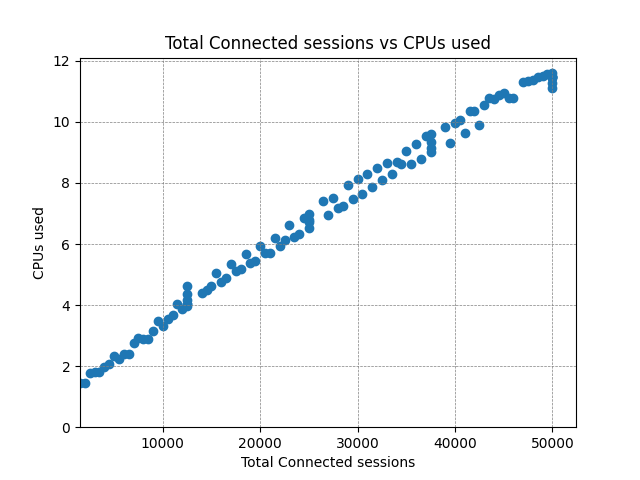
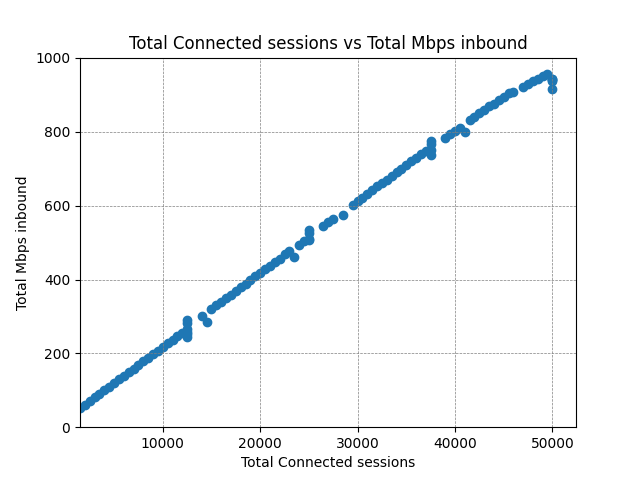
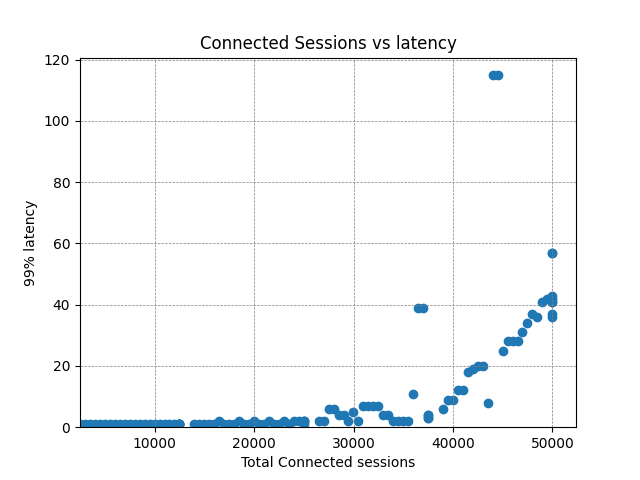
Again, CPU and bandwidth is linear with the load. There’s no additional overhead for delta calculations with more subscribers, since the delta is calculated once and reused among all clients.
The latency sees degradation earlier this time but for most use cases (under 10ms) is unlikely to be a problem until around 40,000 clients, and we don’t exceed our original requirement of sub 50ms until 50,000 clients. One possible explanation for the increase is that CPU for delta calculation is being shared with CPU required to publish data to the network (as well as some other other internal tasks on the server). Shifting the calculation off-server to the publisher process may well flatten this curve.
Scaling the number of subscribers further
What do we do if we want to scale up to more subscribers than this? There’s a common architectural pattern that we can use with Diffusion. Here’s a diagram to explain the approach:
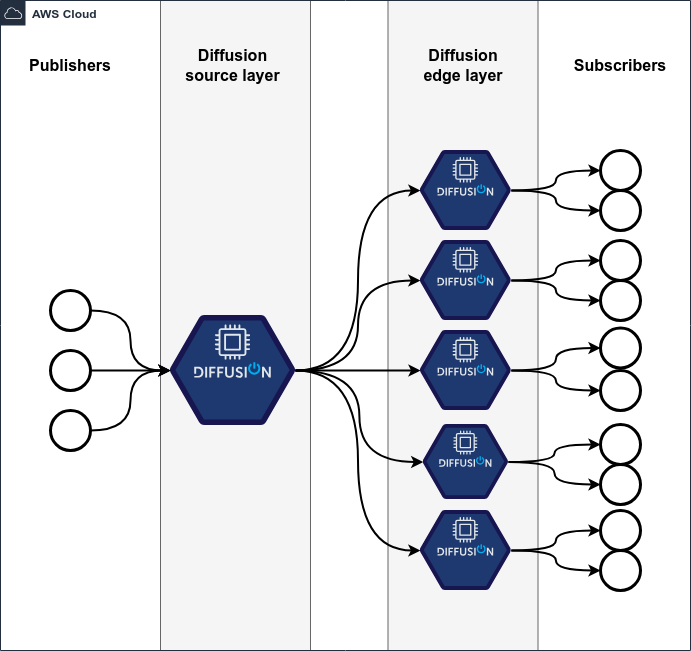
Rather than the subscribers directly connecting to a single server that holds all the data, that “source” server replicates its data to a number of other “edge” servers, and the subscribers get data from those. This means that if we need to handle more subscribers than capacity currently allows, we can add new edge servers as necessary. This is done using the remote topic views feature of Diffusion, and indeed new edge servers can be added on demand.
We will repeat the above test with 5 edge servers, with each of these specified as a 6cin.4xlarge (16 vCPU) instance in AWS. By using the previous test as a guide, we should expect to see around 150,000 connected clients before the latency starts to degrade. Since there is an extra hop between the publishers and the consumers, it would not be unreasonable to see an increase in overall latency.
| Number of clients | Subscriptions per client | Diffusion CPU usage (source) | Diffusion CPU usage (edge) | End-to-end latency | Bandwidth | Bandwidth saving |
|---|---|---|---|---|---|---|
| 50,000 | 100 | 1 CPU | 12 CPUs | 1 ms | 900 Mbps | 83% / 90% |
| 100,000 | 100 | 1 CPU | 24 CPUs | 1 ms | 1950 Mbps | 83% / 90% |
| 200,000 | 100 | 1 CPU | 48 CPUs | 12 ms* | 3900 Mbps | 83% / 90% |
One thing that jumps out here is that the CPU load on the source server is very low. This is because it no longer needs to service tens of thousands of clients and is instead sending data to just 5 “clients”, i.e. the Diffusion edge servers.
The follow graph confirms this:
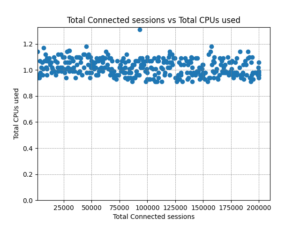
The end-to-end latency is still very low and an increase was not in fact measurable below our 1ms clock resolution until we started to push the system hard around 200,000 concurrent clients; more on this in a moment.
We take the same metrics from the previous test and aggregate them to give the same charts that we showed before.
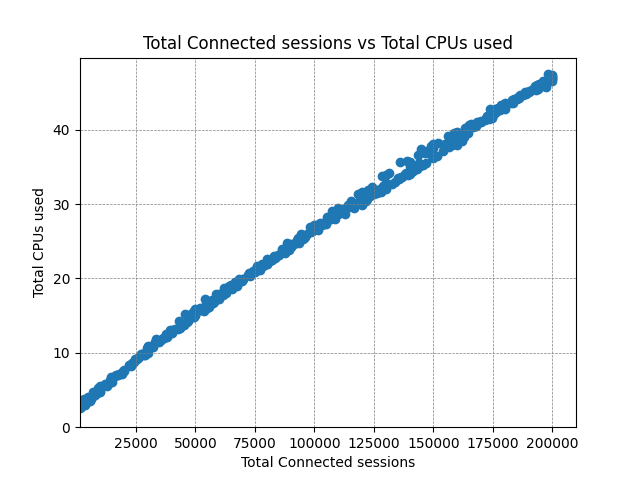
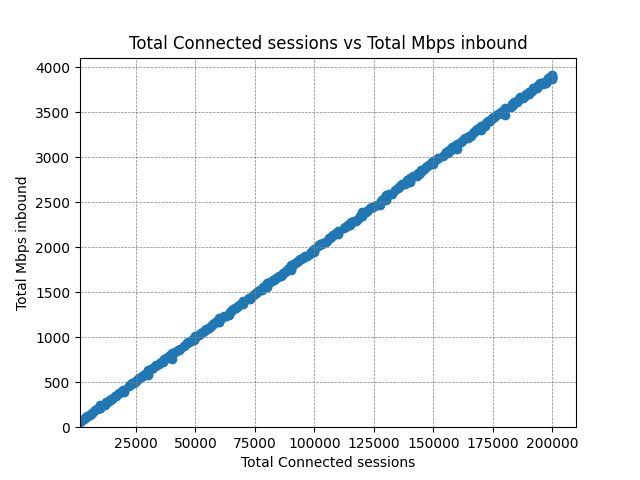
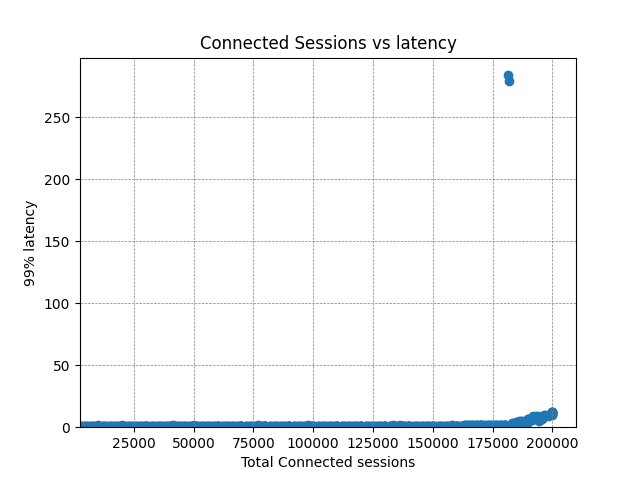
CPU usage and bandwidth across the edge servers continues to scale linearly to just shy of 4Gbps. As mentioned, the latency does trend upwards with an outlier at around 180,000 clients. The true cause of the increase would require further investigation, but it is likely to be some kind of resource starvation; all CPUs are being utilised to their fullest extent, and the volume of traffic may be causing TCP collisions and retransmissions.
Conclusions
Benchmarking tests are generally artificial and these are no exception. However, they are somewhat influenced by real-world scenarios, and we can use them to predict how Diffusion might behave for similar load profiles.
A summary of what these tests have shown is:
- CPU load and bandwidth is predictable, up to a large number of concurrently connected clients.
- Adding an edge layer of Diffusion servers allows for linear scaling of clients far in excess of what is available on a single server.
- Latency is low, and for known inputs can also be well within what most people would consider “real time”.
- Delta compression is a big win – without delta compression, the bandwidth usage at 200,000 clients would be in the region of 22Gbps, so this is a huge win if paying for data egress from a cloud provider.
Further reading
BLOG
The Game-Changer: Change Data Capture (CDC)
March 17, 2025
Read More about The Game-Changer: Change Data Capture (CDC)/span>

BLOG
100 million updates per second - Landmark Diffusion cluster performance
July 02, 2024
Read More about 100 million updates per second - Landmark Diffusion cluster performance/span>
BLOG
Creating a WebSocket Server for PubSub
June 28, 2024
Read More about Creating a WebSocket Server for PubSub/span>




